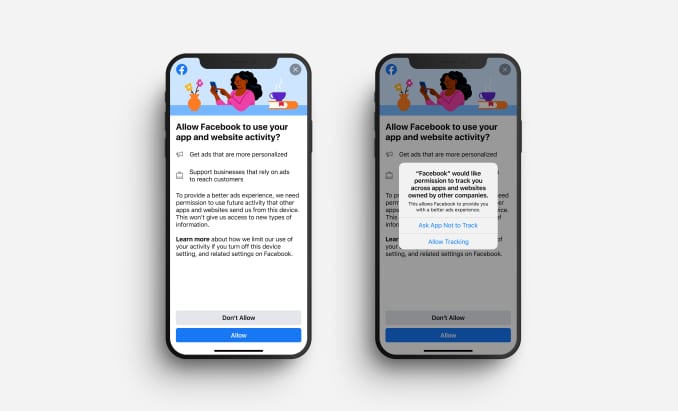
Facebook is guilting people who use their iPhone app. iOS 14’s App Tracking Transparency now requires app makers to explicitly get people’s assent to be tracked. If the phone user declines, iOS only sends generic information that’s really hard to trace back to any identifiable person.
Obviously, this works against Facebook’s interests. It’s built a seven-hundred-billion-dollar company over fifteen years on the back of a sophisticated, extremely aggressive data collection and ad display business.
Facebook’s tried public pressure and PR to lobby against this intervention, arguing that this opt-in hurts not it, but small businesses, who rely on Facebook ads to target would-be customers.
Now Facebook’s building that argument right into its app, with a full-screen appeal to its users to allow themselves to be tracked in detail, so that small businesses may thrive. First reported by CNBC, here is what the screen supposedly looks like (left, before Apple’s prompt to the right):
Facebook’s CEO has said publicly that the company sees Apple as a competitor because “has every incentive to use their dominant platform position to interfere with how our apps and other apps work, which they regularly do to preference their own… Now Apple may say that they’re doing this to help people, but the moves clearly track their competitive interests.”
A few days ago I took a nap and set the DND –do not disturb– on a timer for 1h. Once the timer finished it went by default to “Turn off DND”, which is the same as “disturb me please”… Because of this I was wondering when did the “disturb” mode became (sic) the default? This applies to my phone as well, which I always have with DND turned on. How is it that we have to turn on DND. Shouldn’t it be “turn on disturb mode”?
Some of the answers I found worth sharing:
people generally want to be disturbed by notifications. Just consider how many people don’t keep their phone in silent mode. I don’t think it’s the ideal way to live, but people love running over to their phone to see if it’s a new WhatsApp message that cause the ping.
At the beginning of the smartphone era, there just weren’t that many disruptions to warrant a DND mode. Most notifications were interesting. And we didn’t have wearable devices tethered to phones or computers either. The normalization of distraction kind of got us by surprise, society-wide, and it’s only now that new UX patterns are developing to help people manage it.
My theory would be that that:
> “disturbable by default” is a carry-over from landline-only time calls where rarer in landline-only time because they (sometimes) cost money > calls where rarer in particular times (eg late at night) because of a social norm > calls in the middle of the day where probably rarer, but also much easier to ignore because you were not at home and your phone simply run in the void > calls were mostly done by human beings
Now, the “phone calls from a human being who respects social norms or that I simply never hear” have been replaced by “automated notifications from bots in a piece of plastic that’s constantly in my pocket, or text messages from people that expects me to be reachable at any time.”
The browser uses machine learning algorithms to develop a cohort based on the sites that an individual visits. The algorithms might be based on the URLs of the visited sites, on the content of those pages, or other factors. The central idea is that these input features to the algorithm, including the web history, are kept local on the browser and are not uploaded elsewhere — the browser only exposes the generated cohort. The browser ensures that cohorts are well distributed, so that each represents thousands of people.
As someone with a computer science background, I am interested in learning about and following the progress of FLOC. As someone who cares about privacy and has invested thousands of hours helping spread awareness, I will avoid information collection for the purposes of displaying ads, period. Whether it’s through cookies or fingerprinting or the supercookies we read about recently, or through federated learning.
FLOC will be rolled out in Chrome in 2021, to people who are logged in to the Chrome browser. My advice from the point of view of privacy is to avoid this altogether. Just follow good hygiene when connected to the Internet on your phone or computer (which is all the time):
[to reduce bandwidth and other overhead] if the same image is embedded on multiple websites, Firefox will load the image from the network during a visit to the first website and on subsequent websites would traditionally load the image from the browser’s local image cache…
Unfortunately, some trackers have found ways to abuse these shared resources to follow users around the web. In the case of Firefox’s image cache, a tracker can create a supercookie by “encoding” an identifier for the user in a cached image on one website, and then “retrieving” that identifier on a different website by embedding the same image.
Constructing trackers with this level of sophistication and building distribution of these shared images across websites is not a trivial effort.
For this effort to make monetary sense, advertising and tracking companies need to collect vast amounts for a vast number of people – including you and me – so that even when a tiny fraction of that is useful, it makes enough money to pay for all the engineering and distribution. That means you’re up against a machine that is as aggressive as it is technically sophisticated.
Likewise, Mozilla. How does Firefox disrupt supercookie tracking without fetching an image afresh every time, even if it’s the same image?
[Firefox] still load(s) cached images when a user revisits the same site, but we don’t share those caches across sites. We now partition network connections and caches by the website being visited. Trackers can abuse caches to create supercookies and can use connection identifiers to track users. But by isolating caches and network connections to the website they were created on, we make them useless for cross-site tracking.
Given the vast number of websites that the average person jumps through over any given week, this is not easy to pull off.
I don’t use the term ‘war’ lightly. But this is absolutely a war on your privacy.
It doesn’t matter whether you value your data or not (you should), it’s that you don’t get to choose. Supercookies show that an immense amount of know-how and engineering being deployed to strip you of your privacy. Firefox in turn put in a similar amount of counter-engineering to neutralise that threat.
Make sure you move to Firefox, an open source project whose only incentive is to protect you. And keep it updated. And donate to Mozilla.
This excellent but dense blog post describes how the team from the website performance company catchjs analysed the top one million pages on the web. They logged what these web pages request, what libraries they use, what errors they throw, and how all of these are correlated to performance – that is, how fast your web browsing experience seems.
If you’re familiar with web tech, it’s worth a read in its entirety.
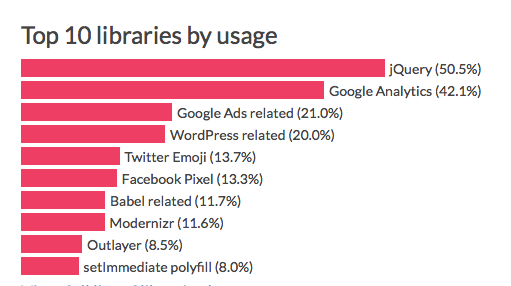
What caught my eye particularly was the use of external libraries:
As the team says
Judging by this top 10, our browsers are mostly running analytics, ads, and code to be compatible with old browsers.
They then go on to identify which of these slow down web pages the most. JQuery’s right up there, along with WordPress’ Woocommerce.
The writers emphasise clearly that correlation should not be linked to causation: the presence of libraries that load faster than the baseline could simply be because they’re the ones typically used by web developers who optimise many other aspects of web pages for performance.
In any case it’s clear from this analysis that ads and analytics – the very things that hijack your attention and privacy – are also what slow down your browsing, burden your internet bandwidth, sap your device’s battery life and take up screen real estate.
It’s shameful that this is what the web has become. But you can fight this.
For a start, use the open-source ad and tracker blocker pi-hole to reclaim some of this. Pi-hole, even out of the box, will block most common analytics and social media plugins and trackers, and can be extended with block lists available freely over the web.
I wrote about my experience following a guide on how you can set up a pi-hole or yourself – for free – that works on all your devices on all networks, at home or outside.
The websites you visit – This is the Big Tech that people are usually concerned about. Whether Facebook.com or Google.com or Amazon.com, incognito mode protects you somewhat here as long as you don’t log in, but even then trakcers now use digital ‘fingerprinting’ that combines several signals to uniquely identify you between visits. Those trackers often send data to other trackers that consolidate this sort of data.
The apps you use – Also includes Big Tech, but goes well beyond them. As we have seen in the article about whether or not to use Whatsap, apps use ‘SDK’s or software packages from a number of tracking companies that record your activity in the app in great detail. This activtiy data is a lot creepier and a lot more valuable than we usually suspect. Consider Netflix’s analytics for modeling your preferences. It tracks
Times when you stop, pause, rewind or fast forward the content.
Days and times when you watch certain content such as rom-coms on Saturday night at 7pm, and Family Guy on Tuesdays at 10pm.
The specific dates you watch (e.g. what movies are popular on Valentines’ day)
Your location when you watch such as your home or at work.
What device you use to watch content. (e.g. TV for movies, Laptop for binge watching shows in bed)
At what points during the show you stop watching and move on. In addition, they also track whether you resume watching later.
What rating you assign a piece of content.
Your search history.
And also
How you browse and scroll through selections. I.e. Do you pause and read descriptions, or just skim through until you see a title/cover you like?
The types of trailers, promotional posters, words, colours and sounds you respond best to i.e. most likely to click on, and follow through.
Similarly, for an ecommerce app, your activity in its app – when you browse, how long you browse, what categories you spend time in, what items you tap preview images for – all this stuff collectively is as valuable as the stuff you actually buy. Same for chat apps. Even if your chat data cannot be decrypted by the company, your behaviour in the app including who you chat with, when, how long, what profiles you tap – all of this builds a picture of you. This The amount of data you can collect on an app – phone make, precise location, contacts – is deeper than websites.
Your DNS provider – DNS is the Internet’s way of translating the internet requests your browser makes and translating them to IP addresses to locate websites, images, CSS stylesheets, fonts and so on. In most cases, your DNS is provided by your ISP. That gives your ISP direct visibility to the sites you visit. If you use another, secure, DNS provider, perhaps one set by your router, or your smart device, or if you change it on your computer/phone/tablet to, say Google or Cloudflare or OpenDNS or some of the others, they now have access to that list. And using a third party DNS provider doesn’t totally hide your web traffic from your ISP either. They may not see the precise DNS request, but they’ll see the reply. You can hide this from your ISP by using a VPN service, but now your VPN provider has access to your traffic [1]
The point of all this is to show that we usually think of privacy in the context of the Big Tech USA companies: Google, Amazon, Facebook and similar. That concern is justified. If anything, it’s under-discussed and poorly understood. But the scope of online surveillance is a lot wider and a lot deeper. And significantly more creepy.
Now that you have some idea of what is watching you online, we can get into how you can protect yourself. We’ll discuss that in the coming days.
(Part 3 – a comment on data custody and open source)
Footnotes
[1] Unless you host your own VPN, but that requires technical capability, and if you’re hosting it in the cloud so you can use it both at home and outside, then you’re paying the cloud provider for all the traffic routed through the VPN.
When we read about loss of privacy, it’s usually in one of two contexts:
Facebook and Google tracking ‘everything’
Customer profile and purchase data being stolen from some or the other service that was hacked
And this is true. But they aren’t the only ones who track your activity online:
Other people on a shared computer – this is what incognito mode is for. Now that each of us has a personal phone, tablet, laptop, this isn’t as much an issue as it used to be. Incognito mode is also useful to have websites ‘forget’ you; more later.
Your computer – the operating system that runs on your computer has access to files, note, contacts, calendar, pictures, music, videos – anything that you store on that computer. Even if you encrypt your hard drive, the operating system – Windows or Mac OS – is what does the encrypting.
Your phone – same as above. You’re most likely running iOS/Apple or Android/Google. In the case of Android phones, most phone manufacturers modify Android – for cosmetic reasons and to add phone-specific functionality. Often their apps are the defaults, not Google’s. In any case, that manufacturer also has access to a lot of the data
Your browser – Chrome, Safari, Edge, made by Google, Apple and Microsoft respectively, need to be able to “see” what websites you visit in order to be able to work. Browsers now have you sign in to not just a website but into the browser itself (think Chrome and your Google account) to sync history, bookmarks and extensions across devices – which means the browser not just tracks this information but stores it centrally. Also – the browser sees your activity even in incognito mode or private mode. That mode just means the browser doesn’t save any information.
Your Internet Service Provider (ISP) – all your traffic needs to go through this entity before it connects to the public internet. Your ISP isn’t able to see HTTPS-encrypted traffic, like the contents of your email on gmail.com, but it knows what sites you’re visiting. This isn’t limited just to your computer – any device at home like an Amazon Echo, Google Chromecast, or a Samsung Smart TV (and similar devices from other brands) – that connects to the internet sends data through your ISP. Technically your home router can also see all your data – this is the one that connects your home wifi to your internet service provider – but I don’t know of routers that are known to systematically ‘phone home’ your data. It’s too big a reputational risk.
Your operator/carrier – same as above, when you’re using your mobile data plan. This is true not just of browser traffic, but also when you use apps, like games. Your operator is very likely able to figure out what games you play based on the internet traffic the game generates. Just because you use the Twitter app instead of visiting twitter.com doesn’t mean you’re sending any less data.
(Part 2 – more entities that track you, including the ones you’re concerned about)
In my post last week, I wrote that simply deleting Whatsapp and moving to Telegram or Signal wasn’t going to make much of a difference to your privacy. There are so many other ways that Facebook collects data from you, your phone and your computer:
The subtext of the article was also that you need to think about your privacy as a whole, not just limited to one app or company.
I won’t pretend that thinking about privacy is straightforward (leave alone appealing), but it’s not impossible either. And since the biggest companies today make money directly or indirectly off your data, it’s worth investing time to understand just how much of your data these companies have, how they get them and how it affects you.
We rest in the fact that we’re just one uninteresting person among hundreds of millions of users of Facebook or Google or Amazon and our particular stream of data isn’t worth much:
If only.
But the algorithms that sift through all this data have little to do with the number of people that they draw conclusions for. You could be a nameless, claimless casualty of an incorrect inference that this algorithm makes: Sir Tim Berners-Lee, one of the fathers of the internet, gives one example:
Just think your insurance gets cancelled because you’ve been searching for cancer online too much. But, in fact, you were looking because a friend of a friend had some form of cancer. However, now the system suddenly decides that it’s worth sending you ads about cancer then also it can decide whether it’s worth increasing your insurance premiums, maybe blocking you from taking on a new insurance policy because they’re worried that you might have an existing condition.
Lately with contract tracing apps mandated by governments, you may not have a choice in data being collected about you. Even if there’s location data about millions of people being collected daily, once the central algorithm identifies that someone near you tested positive, you will almost certainly be required to subject yourself to tests, typically at your expense, and be barred from travel until you receive your results.
But today’s geo-location tech can’t identify that the person who tested positive was enclosed in a changing room in a store while you were browsing a clothes rack outside, both masked at the time.
The result? You being inconvenienced unnecessarily in the name of safety because of incorrect conclusions made from data you shared without choice.
Sticking with real life, as an ordinary person among millions of fellow citizens, you may be arrested because surveillance cameras and the associated facial recognition technology misidentified you. This has happened – repeatedly:
The identifications justified Talley’s detention, even though he claimed he had been at work as a financial adviser for Transamerica Capital when the May robbery took place. Talley said he was held for nearly two months in a maximum security pod and was released only after his public defender obtained his employer’s surveillance records. In a time-stamped audio recording from 11:12 a.m. on the day of the May robbery, Talley could be heard at his desk trying to sell mutual funds to a potential client.
The article from which I’ve taken the quote is an detailed dismal tale of how the person, wrongly identified, had his life turned upside down trying to prove his innocence while struggling to live his life alongside.
The burden of proof, previously solely on prosecutors, has now shifted to an algorithm that doesn’t have to explain itself – another example of how involuntary loss of privacy, this time through surveillance cameras – severely affected an otherwise unremarkable person.
Whether on the Internet or in the real world, it’s easy for your data to be turned against you, even if inadvertently or accidentally. This has nothing to do with how well-known you are, or if someone wants do get back at you.
In this new world, it’s important for you, me, our families – everyone – to understand our loss of privacy and then form our own plan to reclaim it.
Startup Twitter is a lot about constant hustle. There is hardly ever much said about self-care though (even when there is, it becomes competitive). At least at some point I hope there’ll be as much virtue-signalling by the same folks about downtime as there is for hustling.