Back in June and July, I spent a month away from Reddit and Twitter, visiting the site only in a strictly time-boxed twenty minutes at the end of the day. During that isolation,
I realised how much the endless rapid scroll-and-read tired my brain out. I was starting each working day with a depleted brain, right after I had refreshed it overnight. Starting my day with my small list of websites and my RSS instead of scrolling through Twitter and Reddit makes for a much clearer rest of the day
– Reflections on the 30 day Twitter-Reddit isolation, July 2020
Another good thing that emerged from that period is my daily practice of 20 minutes of solitude, which I do while sipping my cold brew in the morning. Solitude
… means not simply being alone, but being alone with your thoughts. So watching TV or Netflix, reading a book or articles, listening to music or a podcast, even if alone, do not count as solitude – your mind is still receiving, as the author says, “input from other minds”.
– Solitude, July 2020
This has worked out well for me, and it is now something I look forward to.
However, I’ve slid back into reading unhealthy amounts of Reddit. This chart, from iOS’ Screen Time, shows numbers I am not proud of:
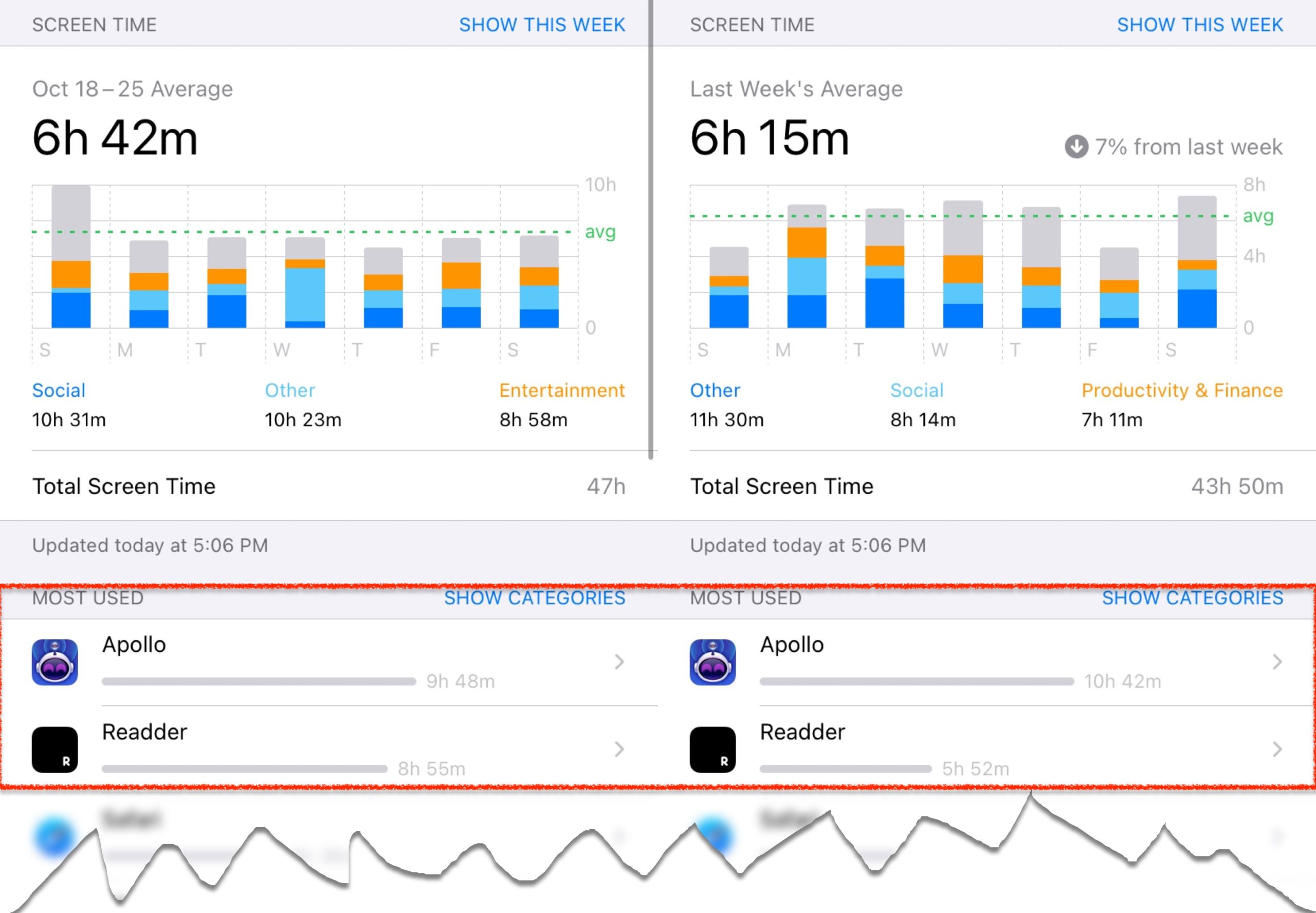
That’s 2 hours 21 minutes every day during the last two weeks of October.
There is much to like about Reddit. I have been deliberate about the subreddits I am on, avoiding negativity and divisiveness. Because the network is anonymous, there’s no envy or fomo on someone else’s achievements – just plain happiness for them.
But not only it is a large time suck, it’s also not time that I spend deliberately. I am not even aware of my opening my Reddit apps, and coming out of a Reddit scroll binge feels not unlike awakening from a deep nap. Hours have passed by without you being aware of them. This is not how I’d like to live, as we just saw:
So I’m checking myself into Reddit Rehab, again. From 6th November to 5th December I’m going to time-box my Reddit usage to twenty minutes at the end of the day. I’m hoping that along with my practice of solitude and of greater deliberation, I’ll be able to use Reddit more consciously.
Let’s see how this goes. I’ll report during and at the end of the isolation.
(Featured image: Frangipani reflected in my morning cold brew)