According to the article, the main difference between these and the cashless payment systems we already use, like prepaid wallets, is “money held on a CBDC app or website will be equivalent to a deposit at the central bank”.
Similarly, the article predicts, such money held in private payment/wallet apps will still be equivalent to being held at the bank, not on the payment providers’ balance sheet. This is unlike today, where adding money into an Amazon Pay prepaid wallet is no longer on your banks’ balance sheet, it’s on whatever Amazon subsidiary holds the prepaid wallet license.
To be clear, none of these central bank digital currencies are really on ‘public’ blockchains, even though governments may piggyback on the term since it’s usually associated with them. They’re centralised, in that while their architecture may nominally resemble decentralised one like, say, the Ethereum blockchain, there’s almost certainly going to be tight control over who can run nodes.
Finally, I was disappointed that the article made only one passing reference to the programmable nature of digital currency, something that is widely done in crypto projects today’s using “smart contracts”, often the most innovative part of such projects. But back in September 2020, we had explored this topic in more detail:
I learnt today that a friend of mine had set up his own personal website. He built it on Notion and linked a domain name to it. That set of Notion pages has a surprising amount of information on it, including what appears to be the beginnings of a knowledge base of the areas he’s built a career in.
His Notion pages have collapsible sections, text, images, embeds, multiple columns – the works. This is by a person who, from what I know, has not had previous experience with WordPress or Weblow or the like.
What Notion has done is simple and yet profound. It has made it super simple to put high quality, information-dense web pages online.
If you are technically adept, you can buy a domain, hosting, install WordPress, a theme or two, a few plugins like Elementor and build your web pages. If you have enough money, you can hire an agency to build a site for you – and train you to add/edit information on it. If you’re the leadership of a company in charge of public-facing properties, you can get a team to build it for you (well, for the company).
But if you’re outside of a fairly narrow set of people, the web is read-only for you.
That’s why social media became such a big deal. It gave everyone an input box and a send button that published to everyone on the Internet. You could fill that box with text, pictures, sounds, whatever you wanted.
But social media is linear, post-oriented and reverse-chronological. As are WordPress.com, Medium, Substack, Revue – all of which are holdovers from the blog era.
For true self-expression, you want to be able to create free-form information. Notion makes that possible. And makes it look pretty, so you aren’t distracted by themeing and customising looks-and-feels. You just focus on how you want to present what is important for you to say.
It does look like the future of publishing.
End note: we’ve spoken time and again about owning your data. Notion is not that. Whatever its data export capabilities may be, it’s still a proprietary format hosted on a third party service. Yet for most people, the benefit of self-expression and one’s own unique online presence is a powerful motivator. And you know what – that might be a good enough trade off for now.
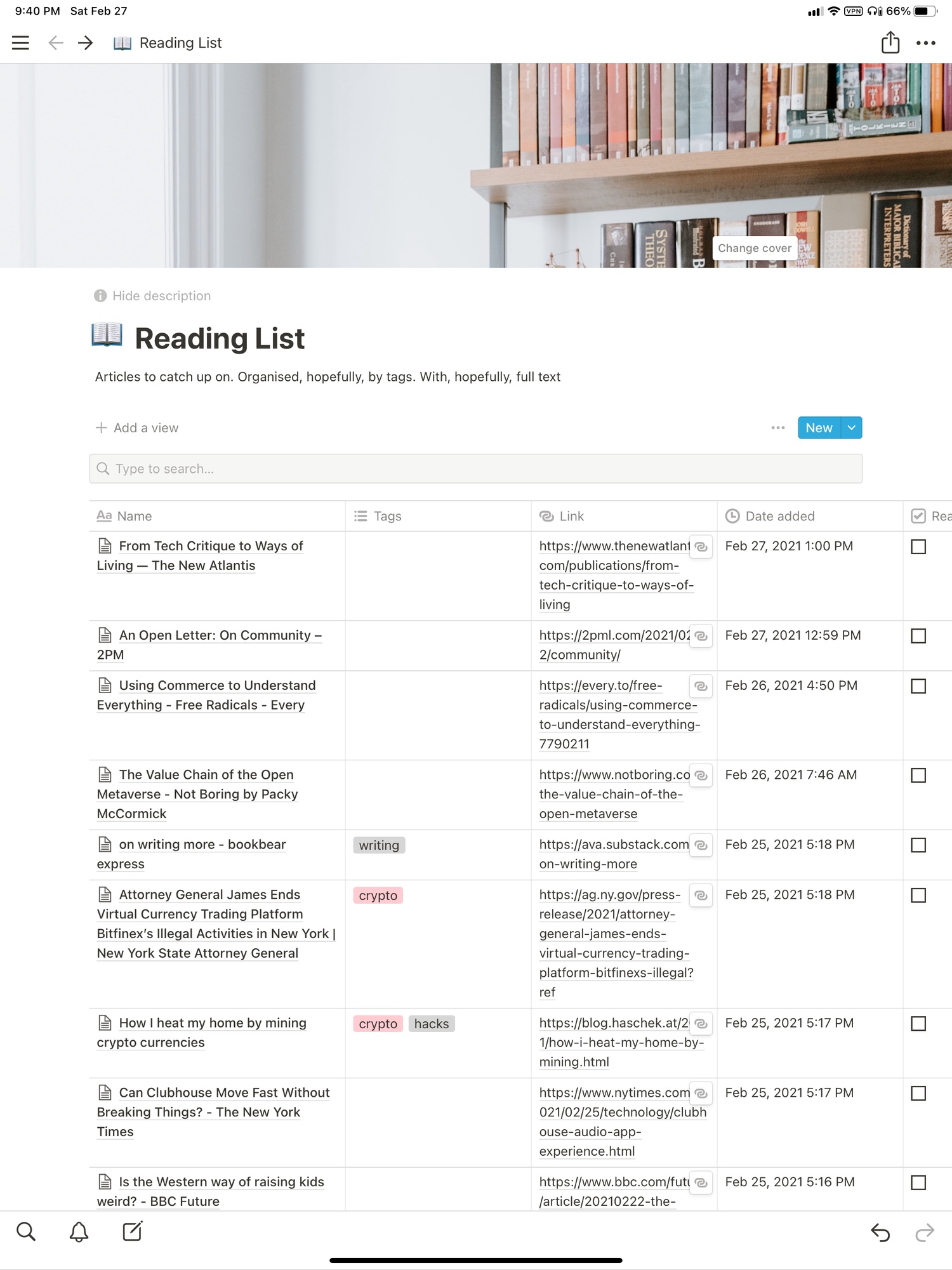
I’ve recently begun using Notion as my read later app.
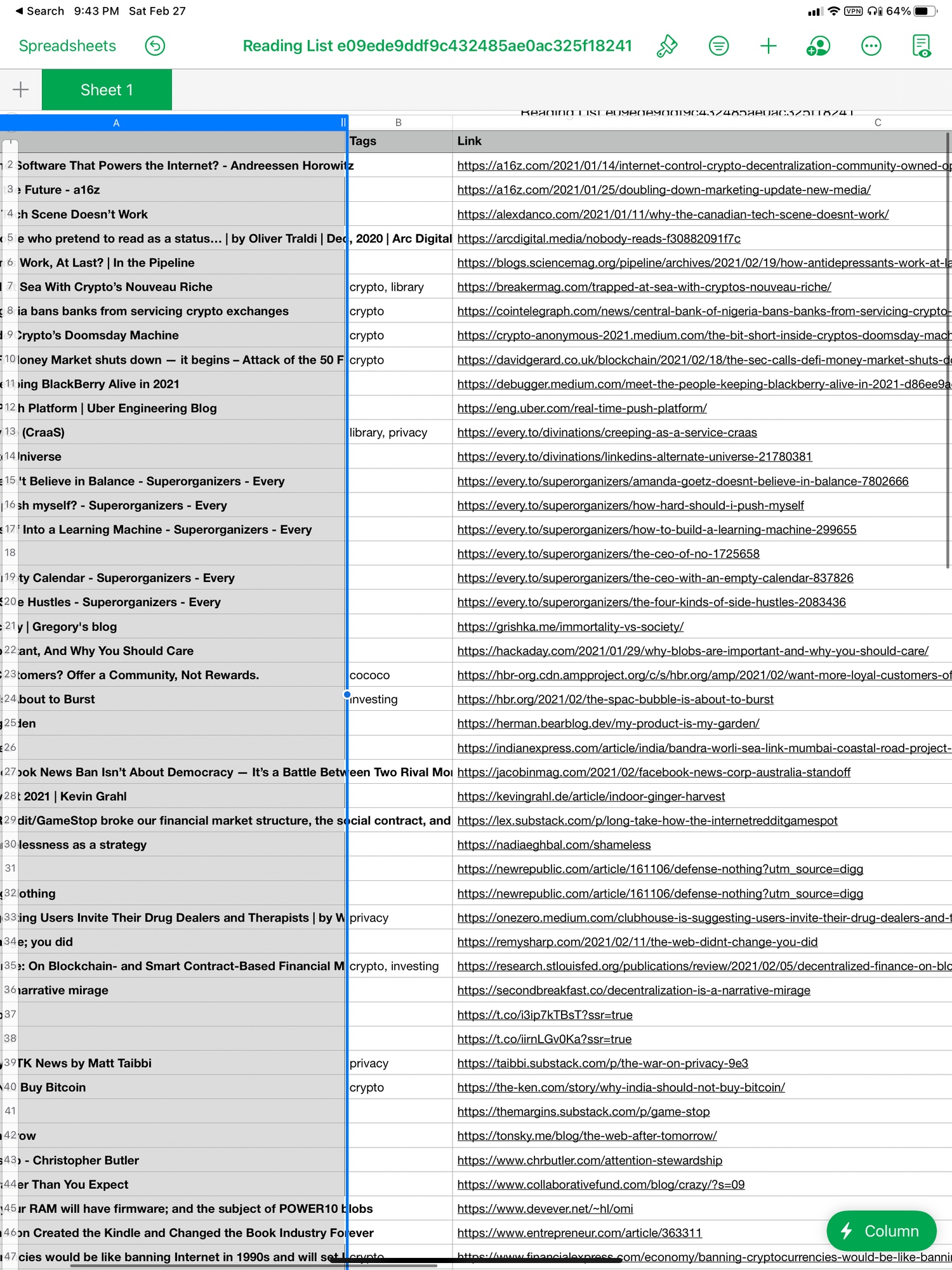
I’ve created a page with a basic database, and Notion’s excellent Share Sheet extension sends web pages from Safari to this database perfectly. Same for the Notion extension for Firefox on the Mac. I just wish both extensions had the ability to edit properties inline so I could add tags right there. This is what my reading list page looks like (the earlier articles have better tagging):
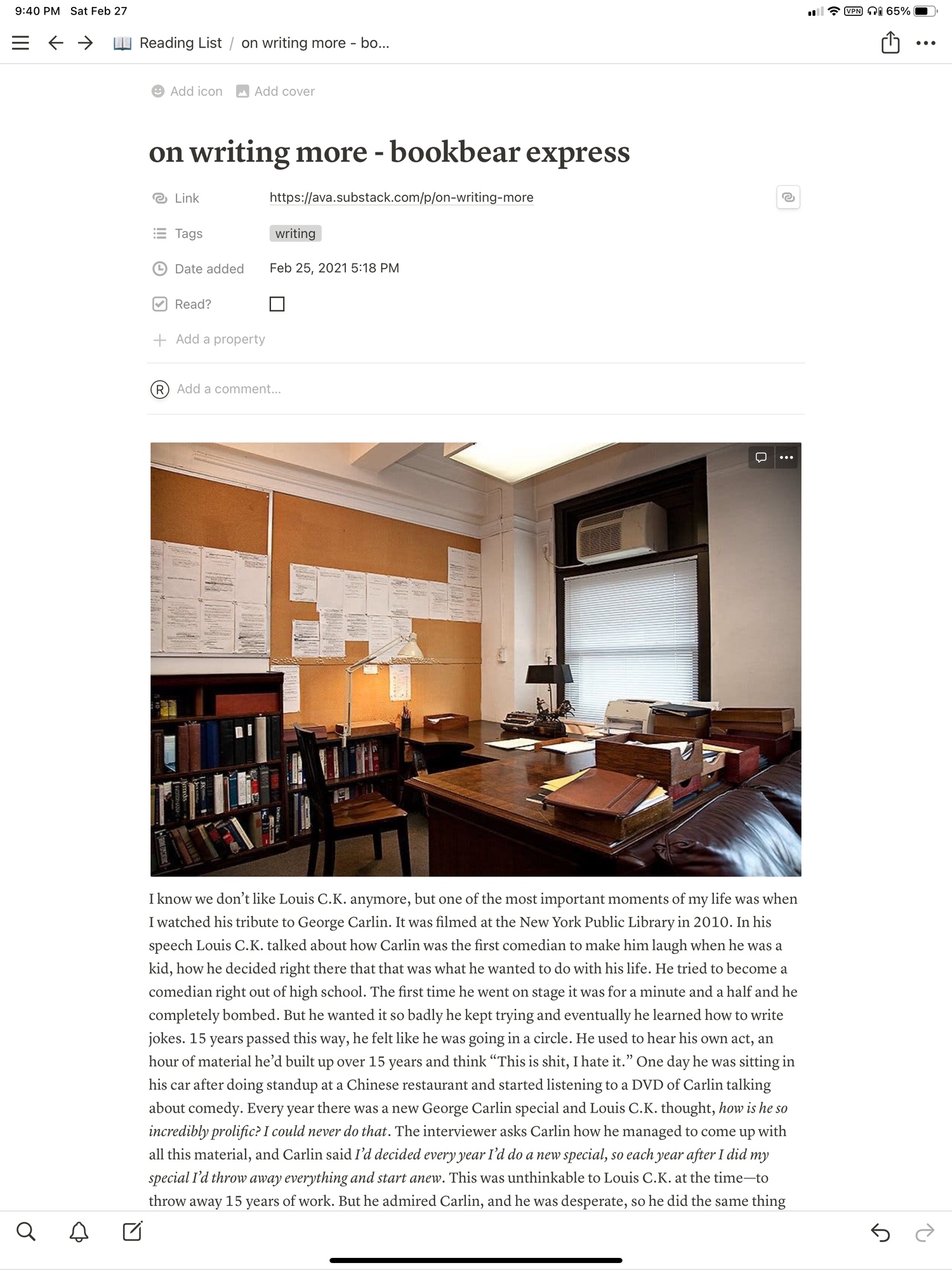
I’m impressed with Notion’s ability to extract text from a web page – it seems to work as well as Instapaper and Pocket, my main read-later services so far. It’s also a pretty good reading experience:
And just like with Instapaper and Pocket, I can export my database to a CSV so I have my URLs in an open format on my hard drive, and not locked away in a closed service. This limitation was what kept me from using Evernote for this:
I didn’t know Dropbox launched a password manager in 2020. This is their product page as of this writing
I used to be an ardent user of Dropbox, with my entire Documents folder stored and synced in the service. I had referred so many people to Dropbox that my initial free 2GB had ballooned to 16GB through rewards. That changed with Dropbox limited the number of devices that you could use with its free plan to three. That made it untenable for me, since I use a variety of computers, tablets and phones and want my data to just be there when I want it. So I haven’t followed Dropbox for a while.
On their most recent earnings call, the CEO talked about “evolving the core Dropbox experience to become the organizational layer across all of our users’ content”.
The CEO described other products:
“We also introduced Vault, an additional layer of security for our customers’ most valuable content, where that content is accessible with a unique PIN code. Users can also grant emergency access to their Vault to trusted friends or family, so they can access the protected content when needed. And finally, we introduced computer backup, which automatically backs up users’ local desktop, documents, and downloads folders to Dropbox for secure access on the go”
This is interesting, because it’s clear now that Dropbox sees itself as another full-featured cloud for people, families and businesses, alongside Microsoft 365 and Google Workplace aka G Suite aka Google Apps.
Nearly a decade ago, they were questioned about being “a feature, not a product“. Since then they seems to have diversified their product from storage and grown enough to become a publicly traded company.
But Dropbox’s weakest proposition might be that its competition has ‘office’ apps – Word, Excel, Powerpoint and Docs, Sheets and Slides (Dropbox’s Paper is interesting but doesn’t hold a candle to office apps). Both Microsoft and Google also offer the sort of storage organisation and sharing features that Dropbox does.
Their pricing also starts at USD 12 per user per month, just like Dropbox’s Business/Standard plan.
For that price, businesses get not just storage and storage management, not just office apps but also mail infra, email clients (Outlook and Gmail) and video conferencing (Teams, and an integrated Meet/Chat/Gmail).
If businesses are paying one of these two companies for their office apps, what’s the case for Dropbox? Put another way, is there a particular segment of the market that Dropbox is chasing?
In addition to those, open source software is also important in the context of what we discussed yesterday: the risks of having your data stored in the Cloud, often in proprietary data formats, with your access to it subject to the terms and conditions of a small set of increasingly dominant tech companies.
Open source software inherently deals with open source formats. It’s difficult to imagine an open source (or free software) project with its own proprietary data format. Perhaps such software may be able to work with data formats from other proprietary software, but that’s a plus. For instance, LibreOffice being able to read and edit Microsoft Office files and GIMP being able to work with Adobe Photoshop files.
Open source and free software projects may offer to host your data in the Cloud, usually for a fee. But there’s almost always the ability for you to host the software on your own server. Bitwarden offers a hosted version, which I use. But I can always host it myself. Likewise, you can either download and self-host Wallabag, the open source read-it-later service, or you can use the Wallabag.it service run by the developers. The choice is yours.
On Mac OS, I try to use open source software unless it’s inconvenient. Over time, I expect to move most of my everyday software to its open source equivalents. For now, here’s a subset.
A lot of what I write is about data custody. It’s a topic that we’re inevitably going to have to debate in the mainstream sometime this decade – I mean prime time conversations on TV. That’ll happen when enough people experience the downsides of having their data reside with just a few large tech companies.
There are many ways things could go wrong with your data in the Cloud.
People could be locked out of their account for some violation of terms of service they weren’t even aware of, or being hacked via social engineering. If it’s their Google account, they lose access to their email, their photos, contacts. This has happened several times. We only rarely hear of it when it happens to someone with a large online following.
One of these companies may have a problem with their data centers. Even though people have access to their accounts, they could find their emails, documents, chats lost.
Companies could suffer an outage. This happens fairly regularly, most recently just a few days ago with the data organisation company Notion. If you can’t access your information at a critical moment – if you need to pull up a receipt number or a scan of a medical prescription – you lose trust in the company you stored your data with.
The ‘cloud’ as the default for our life’s information and documents and photos – this is all very new. Email was probably the first to move to the cloud with Gmail, but even that was just fifteen years ago. That’s barely half a generation.
Each of us needs to spend at least some time thinking about how we’re going to deal with our data when we’re ten, twenty, thirty years older than today. How likely is it we’ll continue use iPhones or whatever they evolve to, to have several terabytes of info in our iCloud Drive or its successor(s), that we’ll keep buying Apple TVs to project our photos on? Ditto with Google. Or {giant trillion dollar corporation}.
We have collectively been exposed to billions of dollars of marketing to keep us from thinking about this, to believe that our data’s safe in the Cloud for now and forever.
To add to that, most of us aren’t ‘tech-savvy’ enough to even know what alternatives exist, much less be able to move to them and use them on an every day basis – why, even if you change your default browser, you’ll be asked if you want to switch back by the browser your computer shipped with (try it – change your default browser to Firefox on Mac OS; Safari will ask you right away if you want to switch back. Microsoft is even worse with Edge)
Finally, neither independent software makers nor open source projects been able to create software that, for the most part, can replace the entire gamut of Cloud-like software that the dominant tech companies provide. For instance, it’s not straightforward to organise your photos using something that’s not Apple Photos or Google Photos or Adobe Lightroom Classic – alternatives exist but they’re not great.
So. It’s not easy and it’s not a solved problem by any means.
Until the Cloud becomes a safe, reliable commodity like the electricity grid or the Internet itself, we’re going to have multiple independent Cloud islands. Apple’s. Google’s. Amazon’s. Microsoft’s. Yandex’s. Dropbox’s. Adobe’s. And a dozen more.
Each are closed worlds, but worlds that hold your life’s work and loves. And your only key, your username and password, isn’t guaranteed to always work.
I believe Bitcoin is one hell of an invention. To have invented a new type of money via a system that is programmed into a computer and that has worked for around 10 years and is rapidly gaining popularity as both a type of money and a storehold of wealth is an amazing accomplishment.
Because of what is going on in the world, besides there being a growing need for money or storehold of wealth assets that are limited in supply, there is also a growing need for assets that can be privately held. Because there aren’t many of these gold-like storehold of wealth assets that can be held in privacy and because the sizes of their markets are relatively small, there exists the possibility that Bitcoin and its competitors can fill that growing need.
He does make a counter-argument against supply: that while Bitcoin itself is limited, there is no limit to the number of cryptocurrencies that can be created in the same manner. As untamperable and un-shut-down-able as Bitcoin.
Speaking of untamperable, Dalio recognises that the biggest threat to Bitcoin is not an attack on the chain itself, but in governments restricting access to it in the first place.
I suspect that Bitcoin’s biggest risk is being successful, because if it’s successful, the government will try to kill it and they have a lot of power to succeed… for good logical reasons governments wanted control over money and they protected their abilities to have the only monies and credit within their borders. When I a) put myself in the shoes of government officials, b) see their actions, and c) hear what they say, it is hard for me to imagine that they would allow Bitcoin (or gold) to be an obviously better choice than the money and credit that they are producing.
This is potentially what could happen in India. While the government recognises – rightly – that cryptocurrency isn’t clearly either a currency or an asset and therefore doesn’t fit into existing regulatory frameworks, its approach to it seems to be one of antipathy. A bill that may be tabled and discussed in the coming weeks is described in the current parliamentary session agenda as one that intends to
… create a facilitative (sic) framework for creation of the official digital currency to be issued by the Reserve Bank of India. The Bill also seems to prohibit all private cryptocurrencies in India, however (sic) it allows for certain exceptions to promote the underlying technology of cryptocurrency and its uses.
Spoonbill snapshots and tracks the changes people make to their Twitter bios, displaying those changes as a timeline. It’s a view into how people express their identity. Especially when that identity needs to be compressed into a couple hundred characters. This article is a good overview of both the service and its implications, using lots of examples such as this one:
The writer says
Spoonbill not only satisfies our tendency for online lurking, but pushes it into voyeur territory; surfacing what’s meant to be hidden is intimate in a way that scrolling a timeline isn’t.
The app isn’t doing anything special in terms of data access. This is an official Twitter API, and it’s how alternative Twitter clients work. What’s special is that it places previously scattered, obfuscated data side by side. That’s what creeps people out.
This is another aspect of privacy isn’t it. We think of it primarily as ‘someone is reading what I type or browse’. It is, but the other aspect is also analysis of data you reasonably expect to be ‘in the wind’.
Say you shopped locally at a grocer’s, a pharmacist’s, a greengrocer’s, your local pub, your barber, and so on. You know that each of them knows what you’re buying. Now imagine they pooled together their receipts and ran a pivot table on them. And now when you visit the greengrocer, (s)he says ‘You bought antacid on Monday? Don’t buy your oranges and kiwis; they might exacerbate it. Here’s some bananas.’ and now you’re freaked out.
Essentially, be aware that most things you put out on the internet that can be seen publicly can also be catalogued, put together and analysed. Just like Spoonbill did. Just because you change something does not mean the previous version is lost forever – no such thing.
(Part 1 – How Facebook’s using guilt to get people to voluntarily opt out of Apple’s privacy protections)
There is a kernel of truth in Facebook’s argument that “with the upcoming iOS 14 changes, many small businesses will no longer be able to reach their customers with targeted ads”. Targeted ads work better than generic, non-targeted ones. And facebook is able to provide user targeting like no other for two reasons: because people share very personal information on Facebook, and because outside of that, Facebook aggressively collects information on people through their activities outside of Facebook, both via businesses who themselves install Facebook tracking to understand their customers better and through other companies they call “Audience Data Providers“
However, Facebook’s ad targeting can be used by businesses large and small. A small burger joint in a city in theory could use Facebook’s sharp targeting to reach its type of customers in its catchment area. But a nationwide burger chain or its franchisee can use the same targeting software to drive people to its store instead, often outspending the independent small business. Facebook makes no promises to small businesses that this is only about them.
It follows that should a person agree to allow themselves to be tracked, Facebook also makes no claim to its users that that information will only be used by small businesses. Just like Facebook’s ad software is available to businesses large and small, user data once collected is also available to any company with a Facebook ad account.
So while Facebook’s ability to track people in such detail doesn’t really give small businesses any sort of sustainable competitive advantage, it doesn’t give its users any choice about trading their data to support an ostensibly noble cause.
Finally, Facebook’s argument holds weight only because of its dominant position in the online ad business, alongside Google. A small ad network would hardly be taken seriously if it claimed to stand up for small businesses nationwide, leave along globally. It’s disingenuous for Facebook to accuse Apple of using its dominant position to push its own agenda while it does the exact same thing.
Apple’s position on privacy is simple. As one of its ads says, “What happens on your iPhone stays on your iPhone”. [1] It is a commitment one party makes to another, no one else, and that party proves it by aligning its interests to the others’.
Facebook’s (opposite) position on privacy is more messy and conflicted. It urges one party (its users) to make sacrifices (allow data tracking) in order to benefit a third party (small businesses) whose thriving only it (Facebook) can ensure. That does not sound like a healthy relationship between any of the parties
As we’ve discussed many times on this site, in the Internet we’ve ended up building, the question of privacy is one of data custody – who you trust with your data. And in that regard, I’d much rather cast my lot with Apple that with Facebook.
End note: One could argue that Google’s stance on privacy, while being the opposite the opposite of Apple’s, is also straightforward: give me data, I’ll make your life dramatically better. Search, Gmail, Google Maps, Google Photos, even the much-missed Google Reader. I’d trust Google with my data way before I trust Facebook.
[1] This is in the context of how Apple’s AI to categorise photos and other data works on-device instead of first sending all data to some central server.
Facebook is guilting people who use their iPhone app. iOS 14’s App Tracking Transparency now requires app makers to explicitly get people’s assent to be tracked. If the phone user declines, iOS only sends generic information that’s really hard to trace back to any identifiable person.
Obviously, this works against Facebook’s interests. It’s built a seven-hundred-billion-dollar company over fifteen years on the back of a sophisticated, extremely aggressive data collection and ad display business.
Facebook’s tried public pressure and PR to lobby against this intervention, arguing that this opt-in hurts not it, but small businesses, who rely on Facebook ads to target would-be customers.
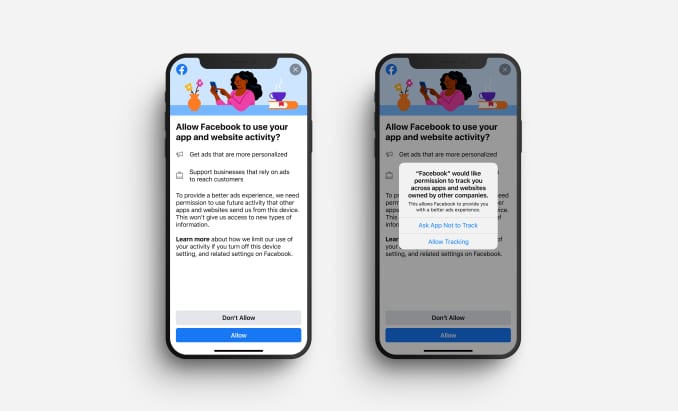
Now Facebook’s building that argument right into its app, with a full-screen appeal to its users to allow themselves to be tracked in detail, so that small businesses may thrive. First reported by CNBC, here is what the screen supposedly looks like (left, before Apple’s prompt to the right):
Facebook’s CEO has said publicly that the company sees Apple as a competitor because “has every incentive to use their dominant platform position to interfere with how our apps and other apps work, which they regularly do to preference their own… Now Apple may say that they’re doing this to help people, but the moves clearly track their competitive interests.”