

Cloudflare is one of my favourite Internet companies. They’ve made previously-enterprise-level services like CDN, denial-of-service protection and HTTPS available to every website owner. They also run the excellent 1.1.1.1 DNS resolution service, which I use on my pi-hole adblocker. I am a Cloudflare customer for this website, and Cloudflare is part of my US stock portfolio as of this writing.
I recently learnt that the Internet Archive and Cloudflare announced an elegant partnership: The Internet Archive operates one of the Internet’s most precious artefacts, the Wayback Machine, which has archived billions of pages from the web’s earliest days (see this website’s pages on the W.M.). It will now begin to also archive pages of Cloudflare customer website. Under the partnership, if a Cloudflare customers website is unavailable for any reason, such as problems with the web host, the Wayback Machine will kick in and serve archived copies of that page instead.
Turning it on on my Cloudflare dashboard only required toggling a switch:
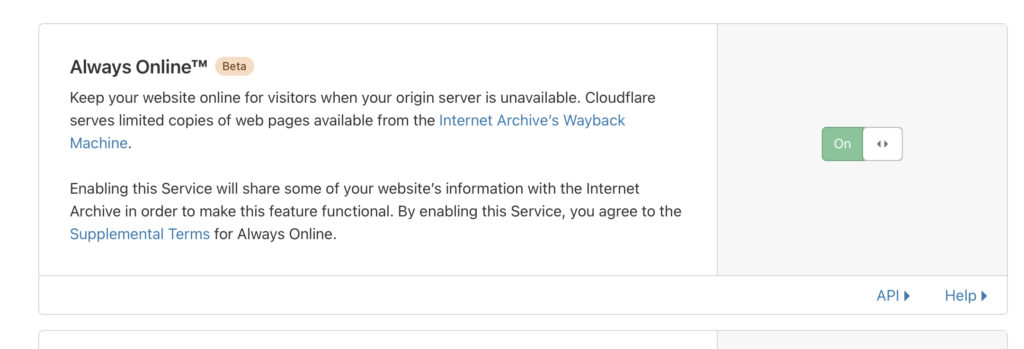
It’s elegant because each party operates what it does best. Cloudflare runs a site’s DNS anyway, and can determine when a site is down. The Wayback Machine archives web pages anyway; it now serves some of them repurposed as cached pages. I imagine these pages are stored differently so as to be retrievable quickly.
Google has long offered cached versions of pages on its search result pages:
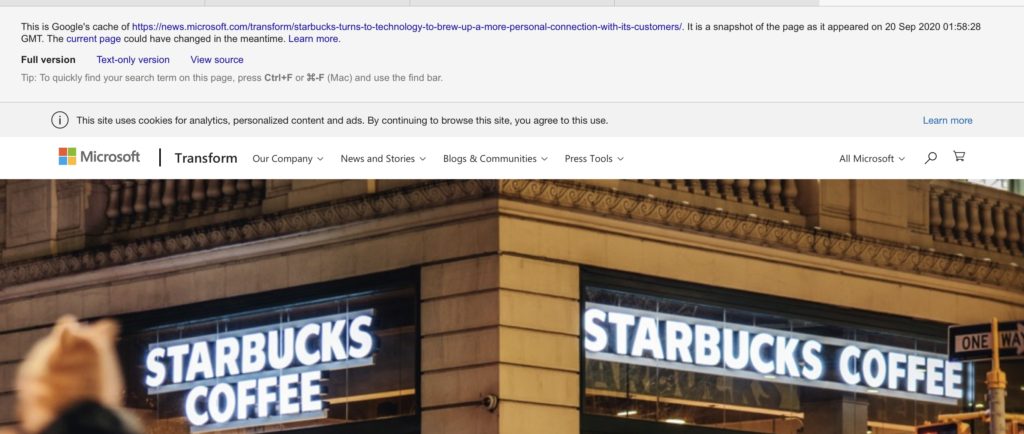
But this partnership is baked into the web – if there’s a problem with a site, pages will be served by the Wayback Machine regardless of whether they were accessed via Google Search or were linked to from another website or were sent via a chat or email. It just works.